Материалы по тегу: intel xe
|
22.09.2025 [13:02], Сергей Карасёв
ASRock представила видеокарты Intel Arc Pro B60 для рабочих станций с ИИКомпания ASRock анонсировала видеокарты Intel Arc Pro B60 Passive 24GB и Intel Arc Pro B60 Creator 24GB для профессиональных рабочих станций, ориентированных на задачи ИИ, большие языковые модели (LLM), дизайн, 3D-моделирование и пр. Новинки выполнены на архитектуре Intel Xe2-HPG и оснащены 24 Гбайт памяти GDDR6 со 192-битной шиной (19 Гбит/с). Модель Intel Arc Pro B60 Passive 24GB, наделённая пассивным охлаждением, имеет однослотовое исполнение. Карта будет доступна исключительно бизнес-заказчикам. В свою очередь, Intel Arc Pro B60 Creator 24GB получила активный кулер (с бесшумным режимом 0dB Silent Cooling) и двухслотовое исполнение. Обе новинки могут использоваться в конфигурациях с несколькими GPU в Linux-средах, что делает их подходящими для серверных развёртываний в рамках масштабных ИИ-платформ. 
Источник изображений: ASRock Видеокарты располагают 20 ядрами Xe2-HPG и 160 матричными движками (XMX). Частота ядра составляет 2400 МГц. Задействован интерфейс PCIe 5.0. Дополнительное питание подаётся через 8-контактный коннектор. Говорится о поддержке Microsoft DirectX 12 Ultimate. Доступны четыре интерфейса DisplayPort 2.1 — основной с поддержкой UHBR13.5 и три дополнительных с поддержкой UHBR10. Видеокарта Intel Arc Pro B60 Passive 24GB имеет размеры 190 × 112 × 19 мм и весит 566 г. Габариты Intel Arc Pro B60 Creator 24GB составляют 271 × 112 × 39 мм, масса — 1118 г.  Некоторые ретейлеры уже начали приём предварительных заказов на эти решения. Так, на сайте американского магазина Central Computers версия Intel Arc Pro B60 Creator 24GB предлагается по ориентировочной цене $600.
21.11.2024 [00:26], Владимир Мироненко
Intel случайно раскрыла, что готовит ИИ-ускоритель Jaguar Shores вслед за Falcon ShoresIntel сообщила о новом ИИ-ускорителе Jaguar Shores, готовящемся в качестве преемника Falcon Shores, упомянув его в презентации во время технического семинара на конференции SC24. Презентация была посвящена чипам Gaudi, сообщает ресурс HPCwire. По мнению источника, упоминание чипа следующего поколения в презентации могло быть случайным. Ожидается, что Falcon Shores поступит в серийное производство в 2025 году. Также в следующем году в массовую продажу поступит ИИ-ускоритель Gaudi 3, представленный ещё в феврале 2023 года. В остальном Intel предпочитает не раскрывать подробностей о своих планах по выпуску ИИ-чипов. Для сравнения, NVIDIA и AMD уже анонсировали планы по выпуску чипов вплоть до 2026–2027 гг. В августе прошлого года Intel сообщила ресурсу HPCwire о работе над чипом Falcon Shores 2, который планируется к выпуску в 2026 году. «У нас упрощённая дорожная карта, поскольку мы объединяем наши GPU и ускорители в единое предложение», — пояснил тогда генеральный директор Патрик Гелсингер (Pat Gelsinger). С тех пор финансовое положение Intel значительно ухудшилось, однако компания продолжает разработку новых ИИ-ускорителей. Пока неясно, будет ли Jaguar Shores GPU или ASIC, но логика именования чипов Intel позволяет предположить, что речь идёт именно о GPU следующего поколения. 
Источник изображения: Intel На данный момент Intel уступила рынок ИИ-обучения компаниям NVIDIA и AMD, сосредоточив свои усилия на инференсе с использованием ИИ-ускорителей Gaudi. Вероятно, Jaguar Shores также будет ориентирован на задачи инференса, который Гелсингер определил как более крупный и перспективный рынок. Однако чтобы догнать ушедших вперёд конкурентов NVIDIA и AMD, Jaguar Shores должен стать действительно прорывным продуктом, полагает HPCwire. «Наши инвестиции в ИИ будут дополнять и использовать наши решения на базе x86, с акцентом на корпоративный, экономически эффективный вывод данных. Наша дорожная карта для Falcon Shores остаётся неизменной», — заявил представитель Intel ресурсу HPCwire несколько месяцев назад.
17.09.2024 [20:59], Владимир Мироненко
Объявленный Intel план реструктуризации ставит под сомнение будущее ускорителей Falcon ShoresВ начале недели Intel разослала сотрудникам письмо с описанием плана выхода из кризиса, который ставит под сомнение будущее ускорителей Falcon Shores, ранее намеченных к выпуску в 2025 году, пишет ресурс HPCwire. Согласно плану, компания сосредоточится на выпуске продуктов на архитектуре x86, что может отразиться на производстве Falcon Shores, поскольку глава Intel Пэт Гелсингер (Pat Gelsinger) ранее заявил, что не будет конкурировать с NVIDIA и AMD в области обучения ИИ. Следующий этап реструктуризации также включает сокращение расходов ещё на $10 млрд и увольнение 15 тыс. сотрудников, из которых 7,5 тыс. уже выразили согласие сделать это на добровольной основе. «Мы должны сосредоточиться на нашей сильной франшизе x86, поскольку мы реализуем нашу стратегию ИИ, одновременно оптимизируя наш портфель продуктов для обслуживания клиентов и партнёров Intel», — подчеркнул в письме Гелсингер. В прошлом месяце на аналитической конференции Deutsche Bank он заявил, что компания покидает рынок обучения ИИ с тем, чтобы сосредоточиться на инференсе, используя сильную сторону чипов x86. 
Источник изображения: Intel Желание Intel сократить расходы и отказаться от неактуальных продуктов может повлиять на реализацию проекта по выпуску Falcon Shores, ускорителя для ЦОД, выход которого неоднократно откладывался. Он является преемником ускорителя Intel Ponte Vecchio (Data Center GPU Max 1550) на базе архитектуры Xe, массовый выпуск которого был фактически прекращён после ввода в эксплуатацию суперкомпьютера Aurora. Ранее Intel отказалась от ускорителей серии Rialto Bridge, а в Falcon Shores было решено отказаться от гибридного подхода, к которому к этому моменту пришли и AMD, и NVIDIA. Впрочем, от ИИ-ускорителей Gaudi компания не отрекается. Intel не ответила на запрос о комментарии о будущем Falcon Shores. И основные разработчики, занимавшиеся этим проектом — Джейсон Маквей (Jason McVeigh) и Раджа Кодури (Raja Koduri) — либо ушли, либо были назначены на другие должности. Гелсингер признал, что Intel сильно отстаёт от своих конкурентов в области GPU и чипов для обучения ИИ, включая NVIDIA, AWS, Google Cloud и AMD. Впрочем, для AWS Intel будет производить в США кастомные процессоры Xeon 6 и ИИ-ускорители (вероятно, это наследники Trainium/Inferentia). 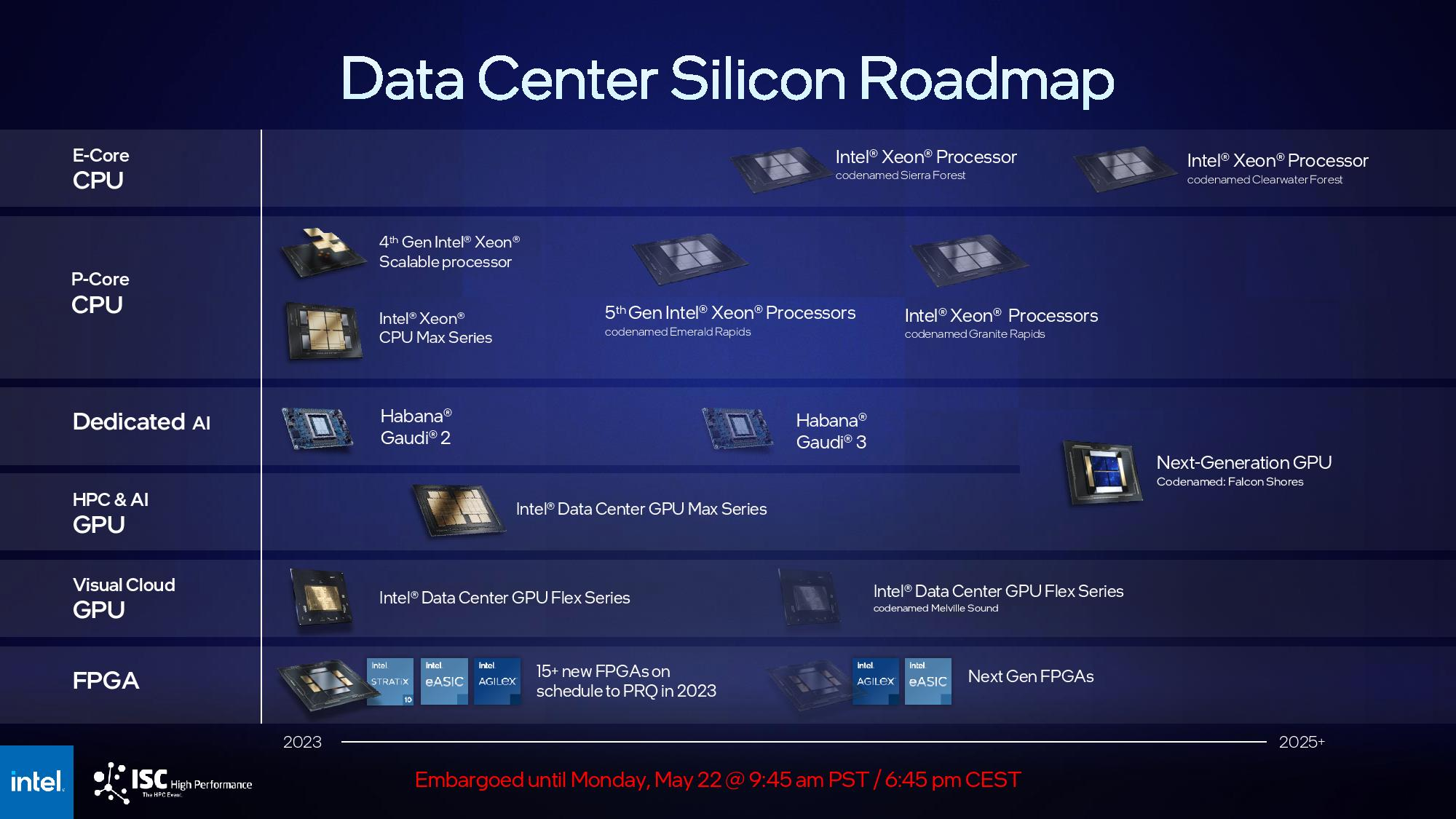
Источник изображения: Intel Также компания отметила отставание на рынке серверов для ЦОД, где сейчас большим спросом пользуются серверы с ИИ-ускорителями. «Где мы ещё не полностью вывели бизнес на хорошие позиции, так это в области CPU для ЦОД», — сообщил в этом месяце финансовый директор Intel Дэйв Цинснер (Dave Zinsner) на конференции Citi Global Technology Conference. Процессоры Xeon Emerald Rapids не оправдали ожиданий компании. Обычный цикл обновления гиперскейлеров в этот раз значительно растянулся, поскольку они активно вкладываются в развитие ИИ-инфраструктуры, попутно увеличивая срок службы традиционных серверов. Следующее поколение Granite Rapids (Xeon 6) должно выйти в начале следующего года. А Diamond Rapids, которые будут выпускаться по техпроцессу Intel 18A (1,8 нм), как ожидается, помогут вывести Intel на лидирующие позиции. Выход на производство по техпроцессу 18A с использованием новой структуры транзисторов RibbonFET и технологии PowerVia является для Intel одной из приоритетных задач. В частности, это техпроцес будет использоваться для выпуска серверных процессоров Clearwater Forest. Пока Intel под натиском AMD активно теряет долю рынка серверных CPU.
21.05.2024 [18:48], Алексей Степин
Intel отказалась от Ponte Vecchio в пользу Gaudi и Falcon ShoresУскоритель Intel Ponte Vecchio на базе архитектуры Xe стал настоящим технологическим чудом, объединив 47 чиплетов в своей сложнейшей, многослойной компоновке на базе EMIB и Foveros. Увы, амбициозный ускоритель задержался: анонсирован он был в 2019 году, но его массовое производство было налажено только к 2023 году. Он продолжит трудиться в уже построенных суперкомпьютерах — в свежем TOP500 система Aurora, использующая данные ускорители, добралась до второго места, хотя постройка машины была завершена почти год назад. Однако новых ускорителей на базе этого решения не будет — проект Rialto Bridge свернут, да и жизненный цикл Ponte Vecchio подходит к концу. Эту архитектуру погубил именно замах: Ponte Vecchio был задуман как универсальный ускоритель, способный эффективно работать практически со всеми существующими форматами вычислений, от полновесного FP64 до характерных для ИИ FP16, BF16 и INT8. Но решения NVIDIA и AMD успели уйти вперёд, появились и более узкоспециализированные ИИ-решения. 
Источник изображений: Intel Причём последние появились и у самой Intel: с приобретением активов Habana Labs компания получила перспективную ИИ-архитектуру Gaudi. С точки зрения рыночных перспектив она оказалась куда лучше Ponte Vecchio, уже во втором поколении чипов успешно сражаясь с решениями NVIDIA, особенно в области удельной производительности. И в области ИИ-ускорителей Intel теперь делает ставку именно на Gaudi3.  В Falcon Shores компания намерена совместить несколько подходов. Согласно последним данным, новинка будет включать в себя элементы архитектур Xe и Gaudi, получит модульный дизайн, поддержку современных ИИ-фреймворков и будет использовать масштабируемые интерфейсы ввода-вывода и HBM3e. Выпуск Falcon Shores намечен на 2025 год. Intel намеревается сфокусировать своё внимание на рынке корпоративных ИИ-систем, для чего планируется как можно быстрее расширять рыночную нишу Gaudi. Однако для рынка HPC ведущей связкой пока останется Xeon с ускорителями серии Max.  Следует отметить, что фокус на специфичных для ИИ архитектурах не означает экономичность. Если самый быстрый вариант Ponte Vecchio в лице OAM-ускорителя Data Center GPU Max 1550 имеет TDP 600 Вт, то у Gaudi3 даже с воздушным охлаждением этот показатель вырастет до 900 Вт. Это вынуждает использовать формат OAM 2.0, но для Falcon Shores и он не подойдёт — Intel говорит уже 1500 Вт, что больше, нежели у NVIDIA Blackwell с его 1200 Вт.
10.04.2024 [14:14], Сергей Карасёв
Intel представила видеокарты Arc для встраиваемых решенийКорпорация Intel анонсировала видеокарты серии Arc Aхx0E, предназначенные для применения в различных встраиваемых устройствах и системах небольшого форм-фактора. В общей сложности дебютировали шесть моделей: Arc A310E, Arc A350E, Arc A370E, Arc A380E, Arc A580E и Arc A750E. В основном это встраиваемые версии видеокарт, которые уже доступны на рынке. При этом изделия подверглись некоторым доработкам с учётом сферы их применения. Ускорители насчитывают от 6 до 28 ядер Xe. Количество исполнительных блоков варьируется от 96 до 448. Объём памяти GDDR6 у младших вариантов составляет 4 Гбайт, а пропускная способность памяти у версий начального уровня составляет 112 Гбайт/с. Для A380E указаны 6 Гбайт и 186 Гбайт/с. А вот для A580E и A750E параметры памяти не указаны. 
Источник изображения: Advantech Производительность INT8 варьируется от 49 до 235 TOPS. Быстродействие на операциях FP16 составляет от 24,6 до 117,6 Тфлопс, на операциях FP32 — от 3,1 до 14,7 Тфлопс. Говорится о совместимости с Windows 10/11, Windows 10 LTSC и Linux. 
Источник изображения: Intel В зависимости от модификации видеокарты Arc Aхx0E могут использоваться для решения таких задач, как распознавание лиц и речи, приложения ИИ, обработка медиаданных и пр. Поставки начнутся в текущем месяце. Решение будут доступны для заказа в течение пяти лет. 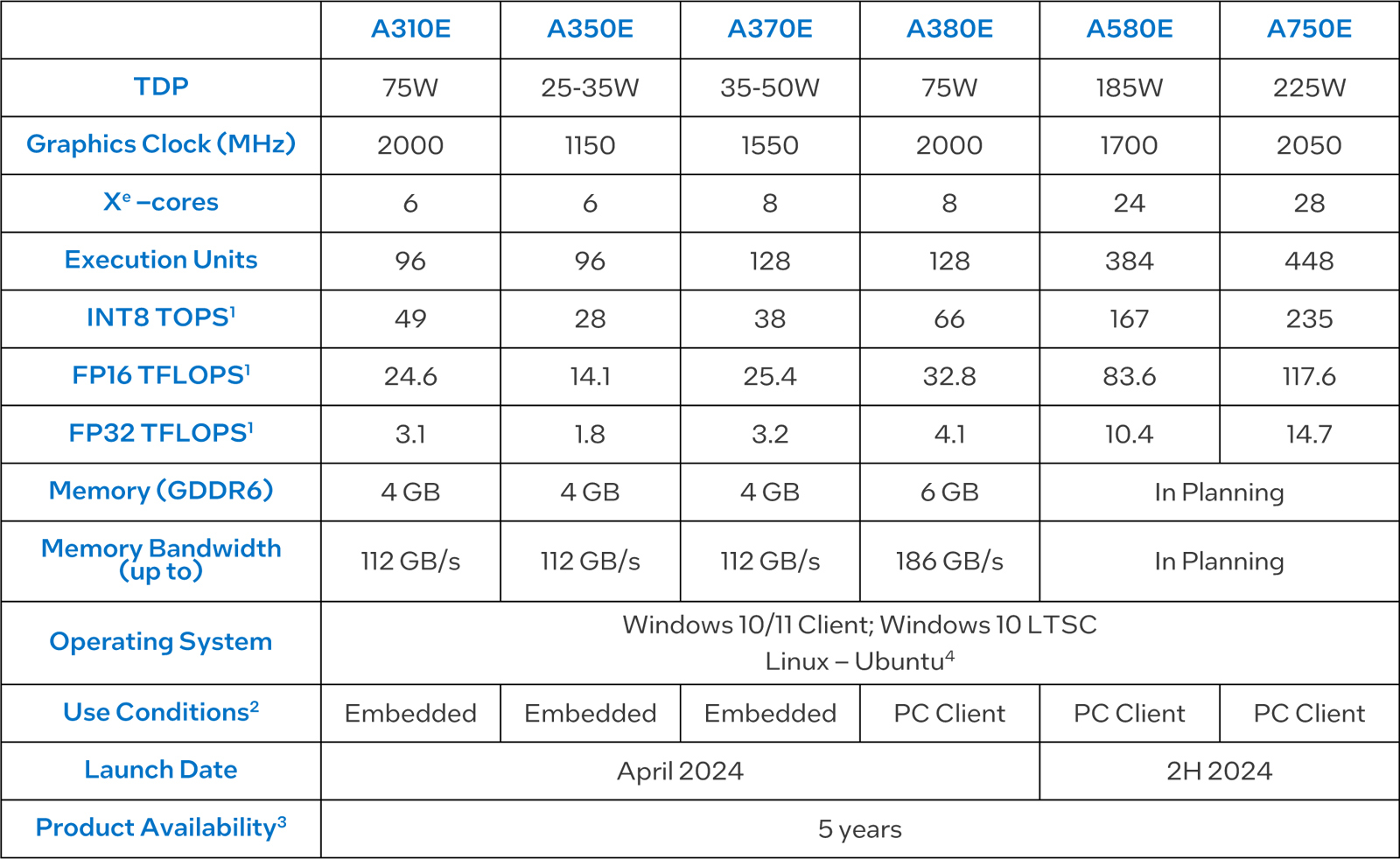
Источник изображения: Intel
01.03.2024 [13:22], Сергей Карасёв
MiTAC представила серверы с процессорами Intel Xeon Emerald Rapids, ускорителями Intel Max и FlexКомпания MiTAC Computing Technology, выкупившая бизнес Intel по производству серверов, анонсировала серверы, выполненные на новейшей аппаратной платформе Intel Xeon Emerald Rapids. В оснащение систем, оптимизированных для HPC-задач и приложений ИИ, входят ускорители серий Intel Max и Intel Flex. Одна из новинок — сервер M50FCP2UR208 в форм-факторе 2U (ранее Intel Fox Creek Pass). Он допускает установку двух ускорителей Intel Data Center GPU Max 1100 (Ponte Vecchio) или четырёх изделий Intel Data Center GPU Flex 140/170 (Arctic Sound-M). Возможно использование чипов Xeon Emerald Rapids с показателем TDP до 350 Вт. Предусмотрены 32 слота для модулей DDR5 суммарным объёмом до 12 Тбайт. Кроме того, есть разъёмы PCIe 5.0 в различных конфигурациях (в зависимости от модификации), десять SATA-портов, слот OCP 3.0 и пять портов USB. Мощность блока питания достигает 2100 Вт. Имеются отсеки для 24 SSD типоразмера SFF. Допускается организация массивов RAID 0/1/5/10. Габариты сервера составляют 770 × 438 × 87 мм. 
Источник изображения: MiTAC Кроме того, дебютировали системы D50DNP1MFALLC и D50DNP2MFALAC (ранее Intel Denali Pass). Первая рассчитана на четыре ускорителя Intel Data Center GPU Max 1550 (Ponte Vecchio), вторая — на четыре карты Intel Data Center GPU Max 1100. Используется форм-фактор 2U4N — 2U-корпус с четырьмя узлами. В зависимости от варианта исполнения задействовано воздушное или жидкостное охлаждение. Говорится о поддержке оперативной памяти стандарта DDR5 (16 слотов; до 2 Тбайт) и высокопроизводительных сетевых карт, в том числе с пропускной способностью до 400 Гбит/с. Среди прочего упомянута поддержка Intel Dynamic Load Balancer, Intel QAT, Intel DSA и Intel IAA. Обе модели получили два коннектора M.2 для SSD, а вариант D50DNP2MFALAC также снабжён двумя фронтальными SFF-отсеками.
14.11.2023 [18:50], Сергей Карасёв
Запущены суперкомпьютеры Dawn, SuperMUC-NG и Crossroads на базе Intel Data Center GPU Max и Xeon Sapphire Rapids
hardware
hpc
intel
intel max
intel xe
sapphire rapids
sc23
xeon
великобритания
германия
суперкомпьютер
сша
Корпорация Intel на конференции по высокопроизводительным вычислениям SC23 рассказала о новых суперкомпьютерах, попавших в ноябрьский рейтинг TOP500. Речь, в частности, идёт о вычислительных комплексах Dawn (Phase 1), SuperMUC-NG (Phase 2) и Crossroads. Система Dawn, созданная специалистами Intel, Dell Technologies и Кембриджского университета, рассчитана на задачи ИИ. В основу положены серверы Dell PowerEdge XE9640 с жидкостным охлаждением. В общей сложности задействованы 256 узлов, в состав которых входят 512 процессоров Intel Xeon Sapphire Rapids — Platinum 8468 с 48 ядрами (96 потоков; 2,1–3,8 ГГц; 350 Вт). Суперкомпьютер Dawn использует 1024 ускорителя Intel Data Center GPU Max 1550. Общий объём памяти DDR составляет 256 Тбайт, а её пропускная способность достигает 157 Тбайт/с. Кроме того, задействовано 128 Тбайт памяти НВМ с пропускной способностью до 3,3 Пбайт/с. Подсистема хранения данных вместимостью 3 Пбайт обеспечивает скорость до 2 Тбайт/с. Агрегированная пропускная способность сети — до 25,6 Тбайт/с. Заявленная производительность достигает 19,46 Пфлопс (FP64). Это соответствует 41-му месту в ноябрьском рейтинге ТОР500. Пиковое быстродействие — 53,85 Пфлопс. Система установлена в лаборатории Cambridge Open Zettascale Lab (Великобритания). 
Источник изображения: Intel В свою очередь, комплекс SuperMUC-NG (Phase 2) смонтирован в Суперкомпьютерном центре Лейбница Баварской академии наук (Германия). Этот суперкомпьютер базируется на серверах Lenovo ThinkSystem SD650-I V3 Neptune DWC с прямым жидкостным охлаждением. Установлены 240 узлов, в состав которых входят в общей сложности 480 процессоров Intel Xeon Platinum 8480L (56 ядер; 112 потоков; 2,0–3,8 ГГц; 350 Вт) и 960 ускорителей Data Center GPU Max. 
Источник изображения: Intel Комплекс SuperMUC-NG (Phase 2) оперирует 123 Тбайт памяти DDR с пропускной способностью до 147 Тбайт/с. Память НВМ такого же объёма обеспечивает пропускную способность до 3,1 Пбайт/с. Применено хранилище на 1 Пбайт со скоростью 750 Гбайт/с. Пропускная способность сети — до 12 Тбайт/с. Суперкомпьютер обладает производительностью 17,19 Пфлопс (FP64): в списке ТОР500 система располагается на 52-й строке. Наконец, суперкомпьютер Crossroads размещён в Лос-Аламосской национальной лаборатории (LANL) Министерства энергетики США. Система обладает производительностью 30,03 Пфлопс (FP64). Задействованы 2600 чипов Intel Xeon CPU Max 9480 с 56 ядрами и памятью HBM. Система находится на 24-м месте рейтинга ТОР500. Всего же в новой редакци рейтинга есть 20 новых машин на базе Sapphire Rapids, из которых пять используют Max-версию процессоров, а также четыре системы с ускорителями Data Center GPU Max.
14.11.2023 [03:20], Алексей Степин
Intel показала результаты тестов ускорителя Max 1550 и рассказала о будущих чипах Gaudi3 и Falcon ShoresВ рамках SC23 корпорация Intel продемонстрировала ряд любопытных слайдов. На них присутствуют результаты тестирования ускорителя Max 1550 с архитектурой Xe, а также планы относительно следующего поколения ИИ-ускорителей Gaudi. 
Изображение: Intel При этом компания применила иной подход, нежели обычно — вместо демонстрации результатов, полученных в стенах самой Intel, слово было предоставлено Аргоннской национальной лаборатории Министерства энергетики США, где летом этого года было завершён монтаж суперкомпьютера экза-класса Aurora, занимающего нынче второе место в TOP500.  В этом HPC-кластере применены OAM-модули Max 1550 (Ponte Vecchio) с теплопакетом 600 Вт. Они содержат в своём составе 128 ядер Xe и 128 Гбайт памяти HBM2E. Интерфейс Xe Link позволяет общаться напрямую восьми таким модулям, что обеспечивает более эффективную масштабируемость. 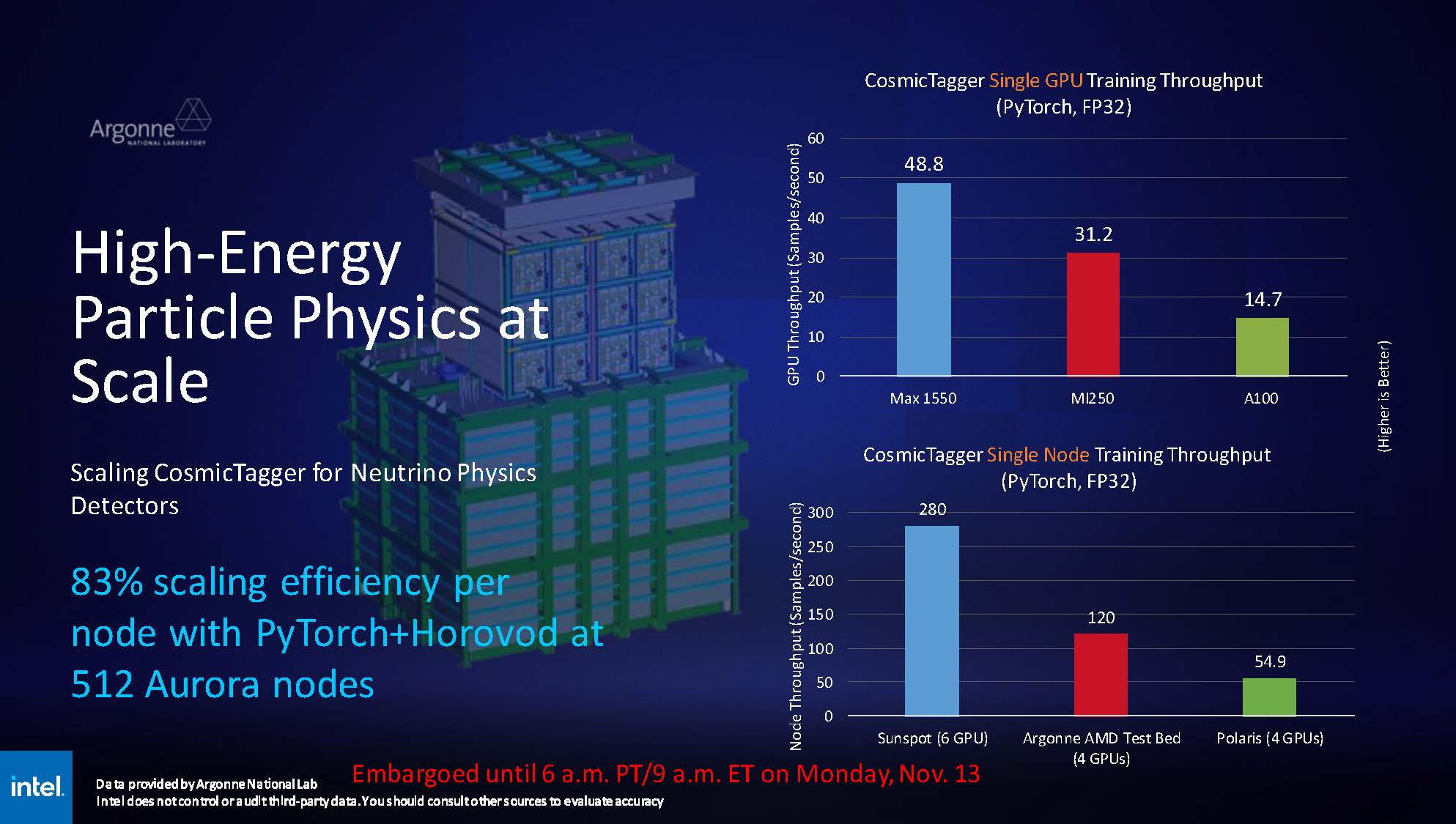
Источник изображений здесь и далее: Intel via ServeTheHome Хотя настройка вычислительного комплекса Aurora ещё продолжается, уже имеются данные о производительности Max 1550 в сравнении с AMD Instinct MI250 и NVIDIA A100. В тесте физики высоких частиц, использующих сочетание PyTorch+Horovod (точность вычислений FP32), ускорители Intel уверенно заняли первое место, а также показали 83% эффективность масштабирования на 512 узлах Aurora.  В тесте, симулирующем поведение комплекса кремниевых наночастиц, ускорители Max 1550, также оказались первыми как в абсолютном выражении, так и в пересчёте на 128-узловой тест в сравнении с системами Polaris (четыре A100 на узел) и Frontier (четыре MI250 на узел). Написанный с использованием Fortran и OpenMP код доказал работоспособность и при масштабировании до более чем 500 вычислительных узлов Aurora. 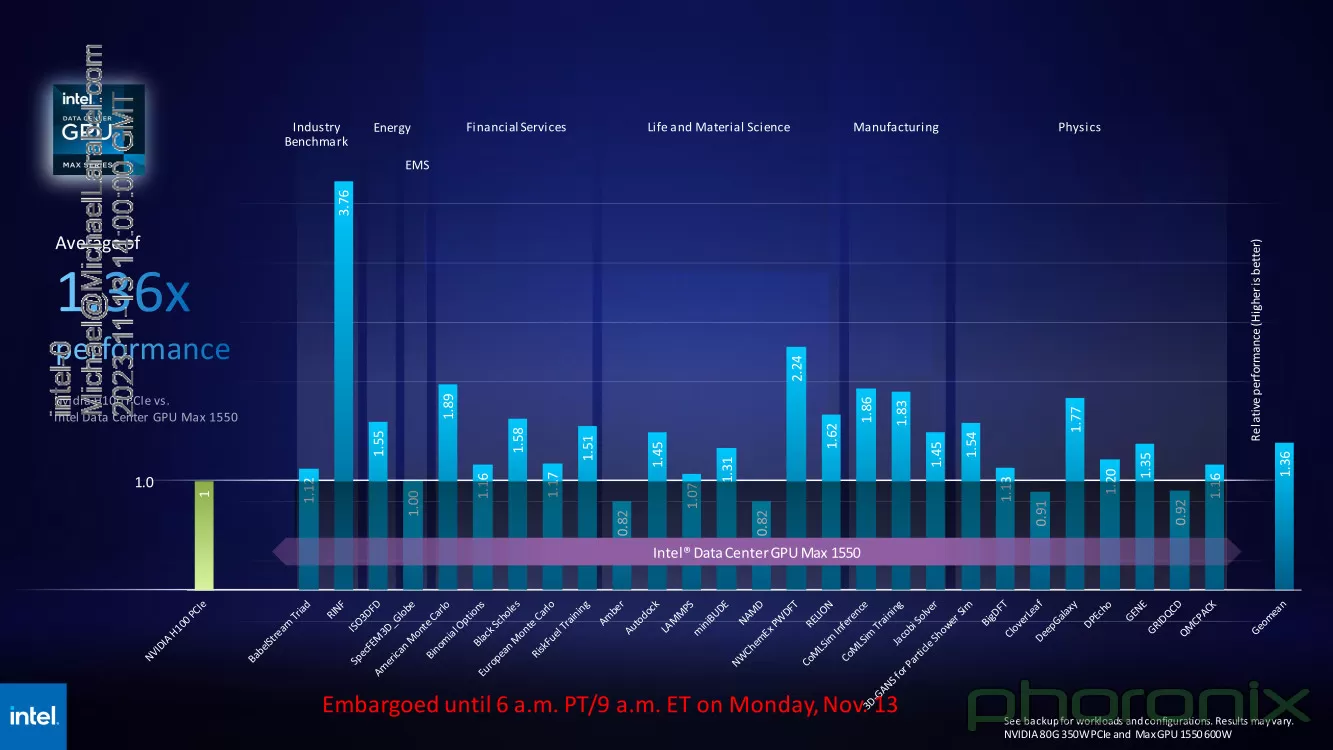
Источник изображения: Intel via Phoronix В целом, ускорители Intel Max 1550 демонстрируют хорошие результаты и не уступают NVIDIA H100: в некоторых задачах их относительная эффективность составляет не менее 0,82, но в большинстве других тестов этот показатель варьируется от 1,0 до 3,76. Очевидно, что у H100 появился достойный соперник, который, к тому же, имеет меньшую стоимость и большую доступность. Но сама NVIDIA уже представила чипы (G)H200, а AMD готовит Instinct MI300.  Системы на базе Intel Max доступны в различном виде: как в облаке Intel Developer Cloud, так и в составе OEM-решений. Supermicro предлагает сервер с восемью модулями OAM, а Dell и Lenovo — решения с четырьями ускорителями в этом же формате. PCIe-вариант Max 1100 доступен от вышеуказанных производителей, а также у HPE. 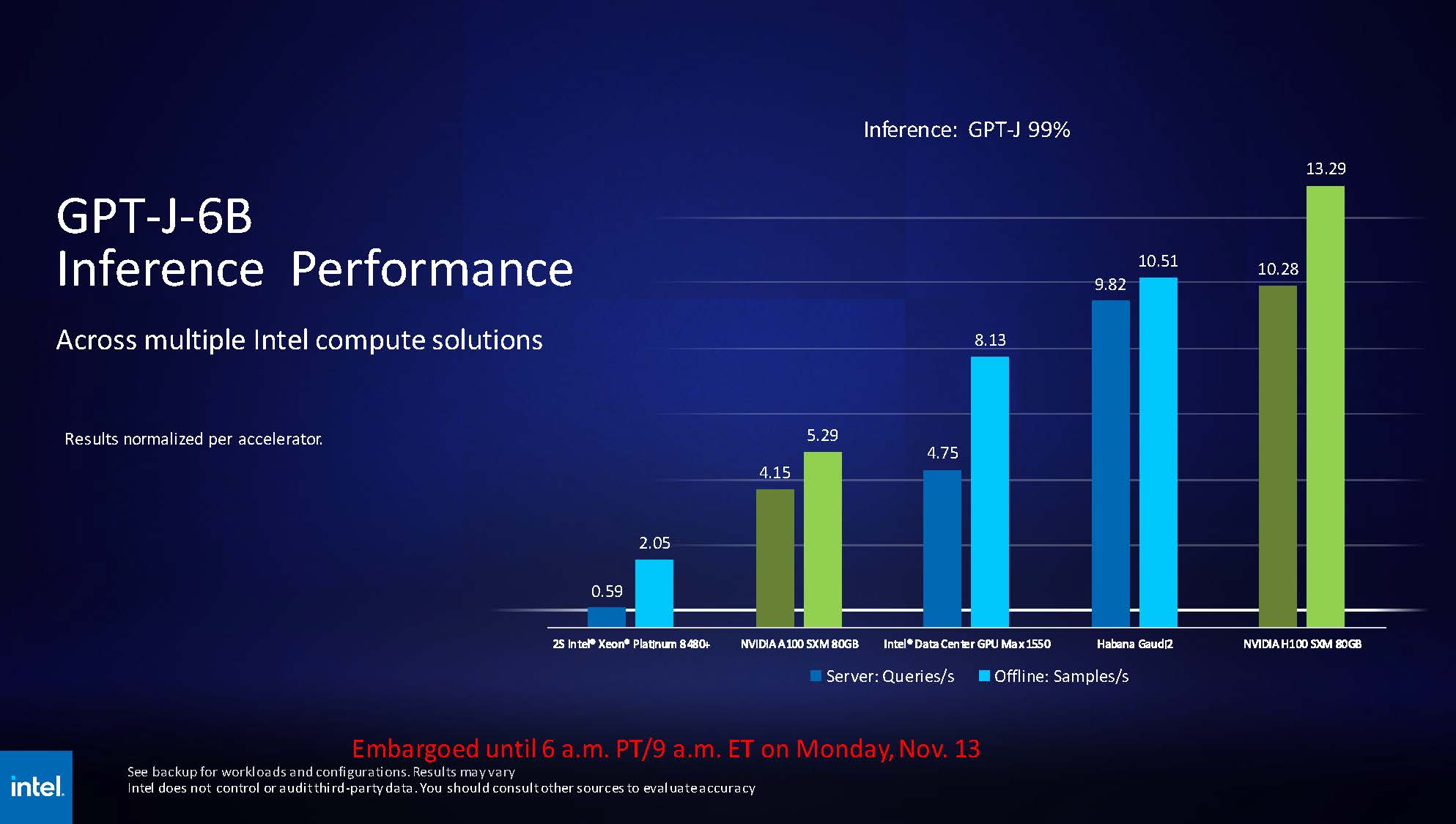 Помимо ускорителей Max, Intel привела и новые данные о производительности ИИ-сопроцессоров Gaudi2. Компания продолжает активно совершенствовать и оптимизировать программную экосистему Gaudi. В результате, в инференс-системе на базе модели GPT-J-6B результаты ускорителей Gaudi2 уже сопоставимы с NVIDIA H100 (SXM 80 Гбайт), а A100 существенно уступает как Gaudi2, так и Max 1550.  Но самое интересное — это сведения о планах относительно следующего поколения Gaudi. Теперь известно, что Gaudi3 будет производиться с использованием 5-нм техпроцесса. Новый чип будет в четыре раза быстрее в вычислениях BF16, а также получит вдвое более мощную подсистему памяти и в 1,5 раза больше памяти HBM. Увидеть свет он должен в 2024 году. 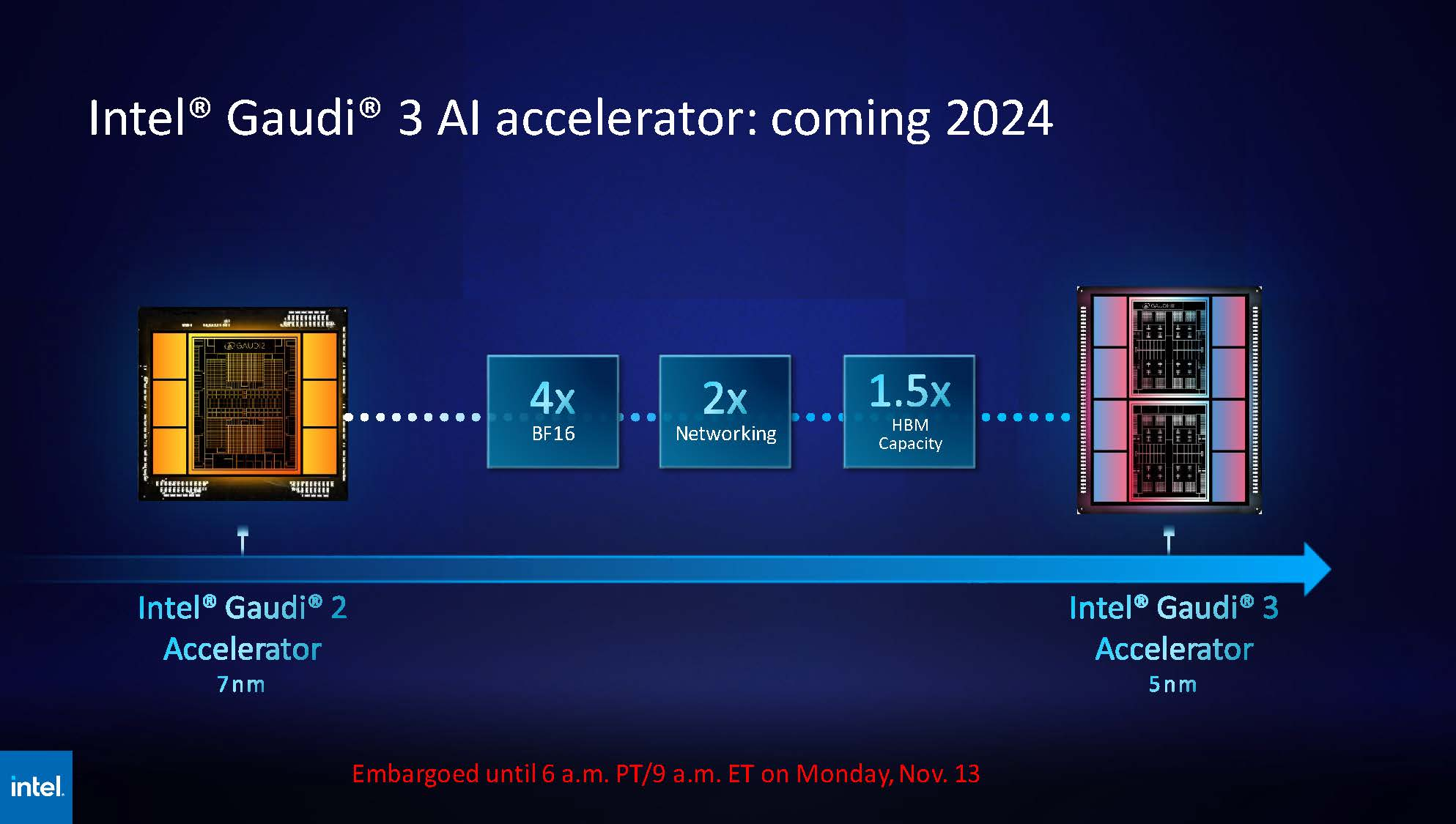 Заодно компания напомнила, что процессоры Xeon Emerald Rapids будут представлены ровно через месяц, а Granite Rapids появятся в 2024 году. В 2025 появится чип Falcon Shores, который теперь должен по задумке Intel сочетать в себе GPU и ИИ-сопроцессор. Он объединит архитектуры Habana и Xe в единое решение с тайловой компоновкой, памятью HBM3 и полной поддержкой CXL. 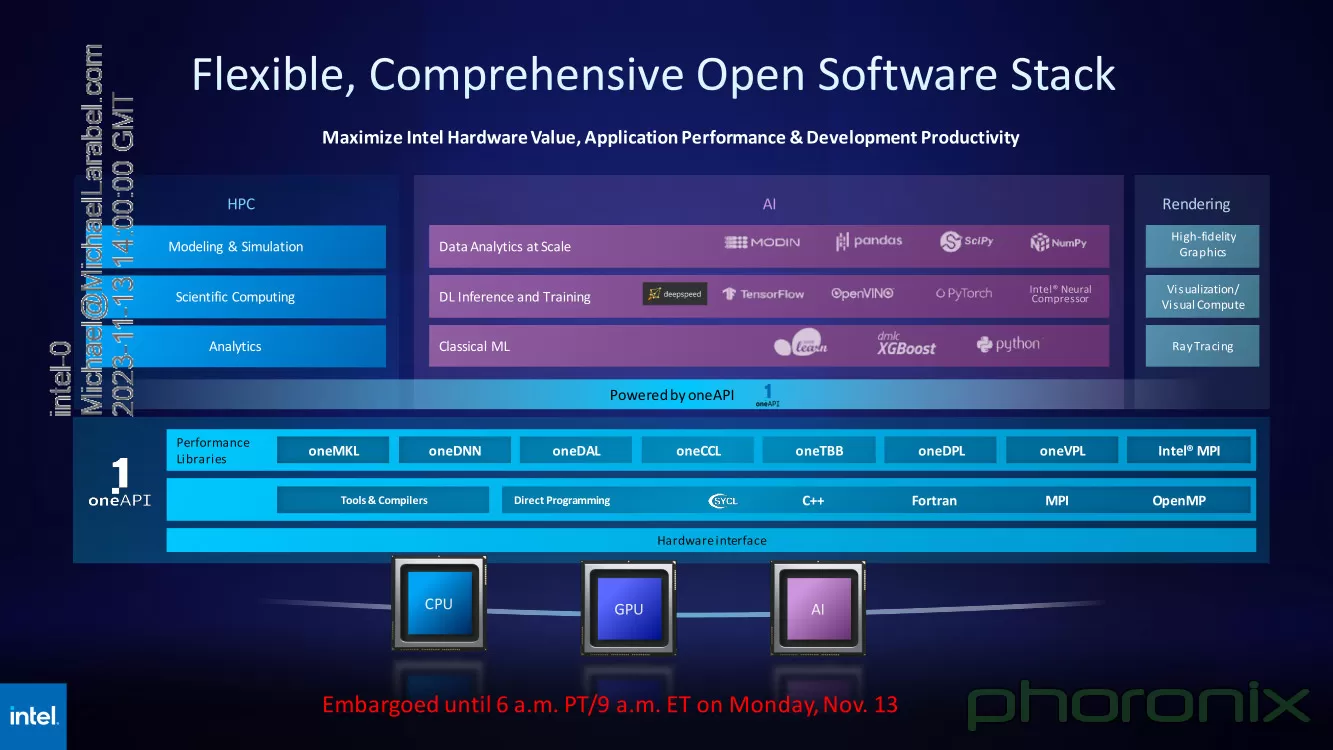
Источник изображения: Intel via Phoronix Следует отметить, что такая унификация вполне реальна: Intel весьма активно развивает универсальный, гибкий и открытый стек технологий в рамках проекта oneAPI. В него входят все необходимые инструменты — от компиляторов и системных библиотек до средств интеграции с популярными движками аналитики данных, моделями и библиотеками искусственного интеллекта.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 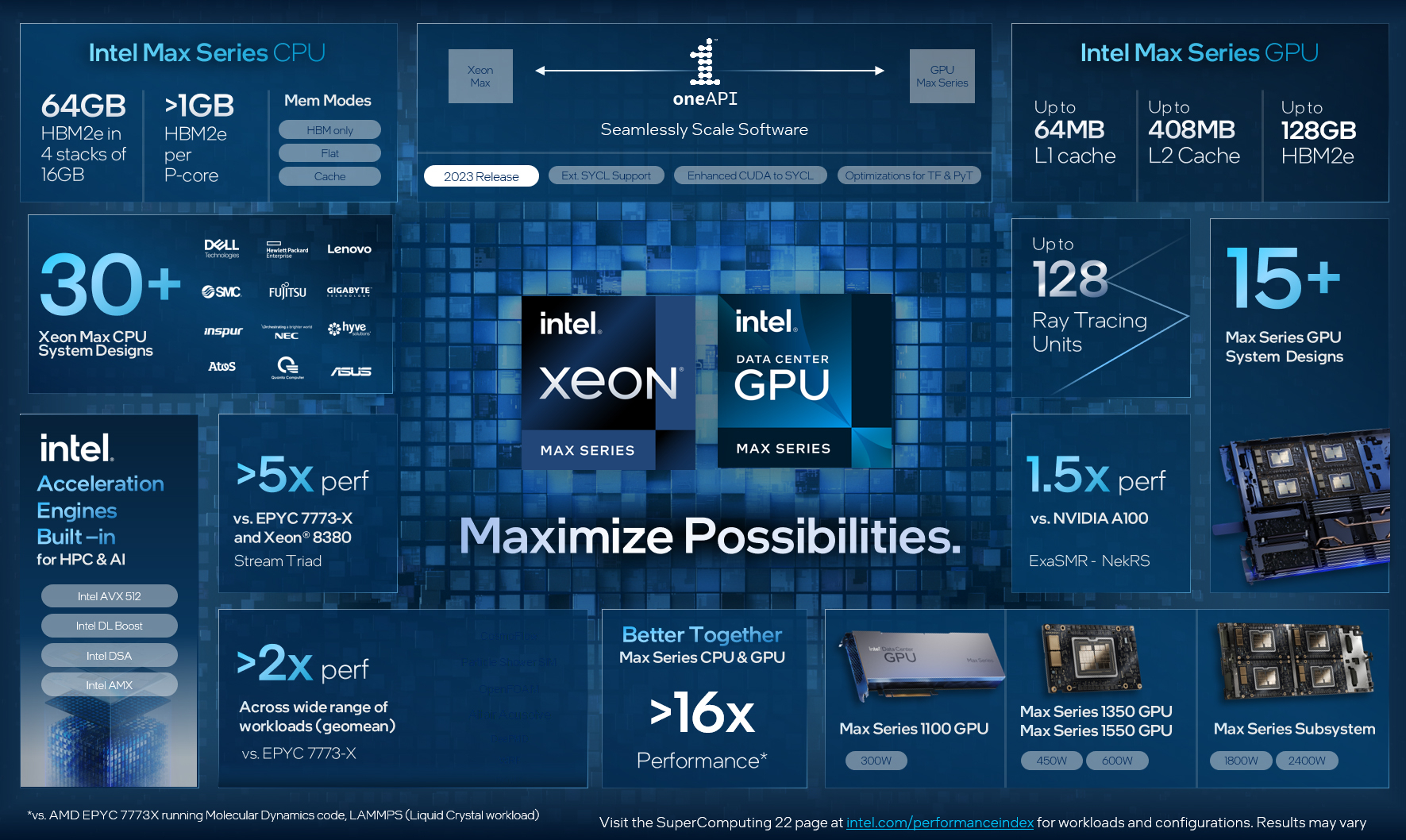
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 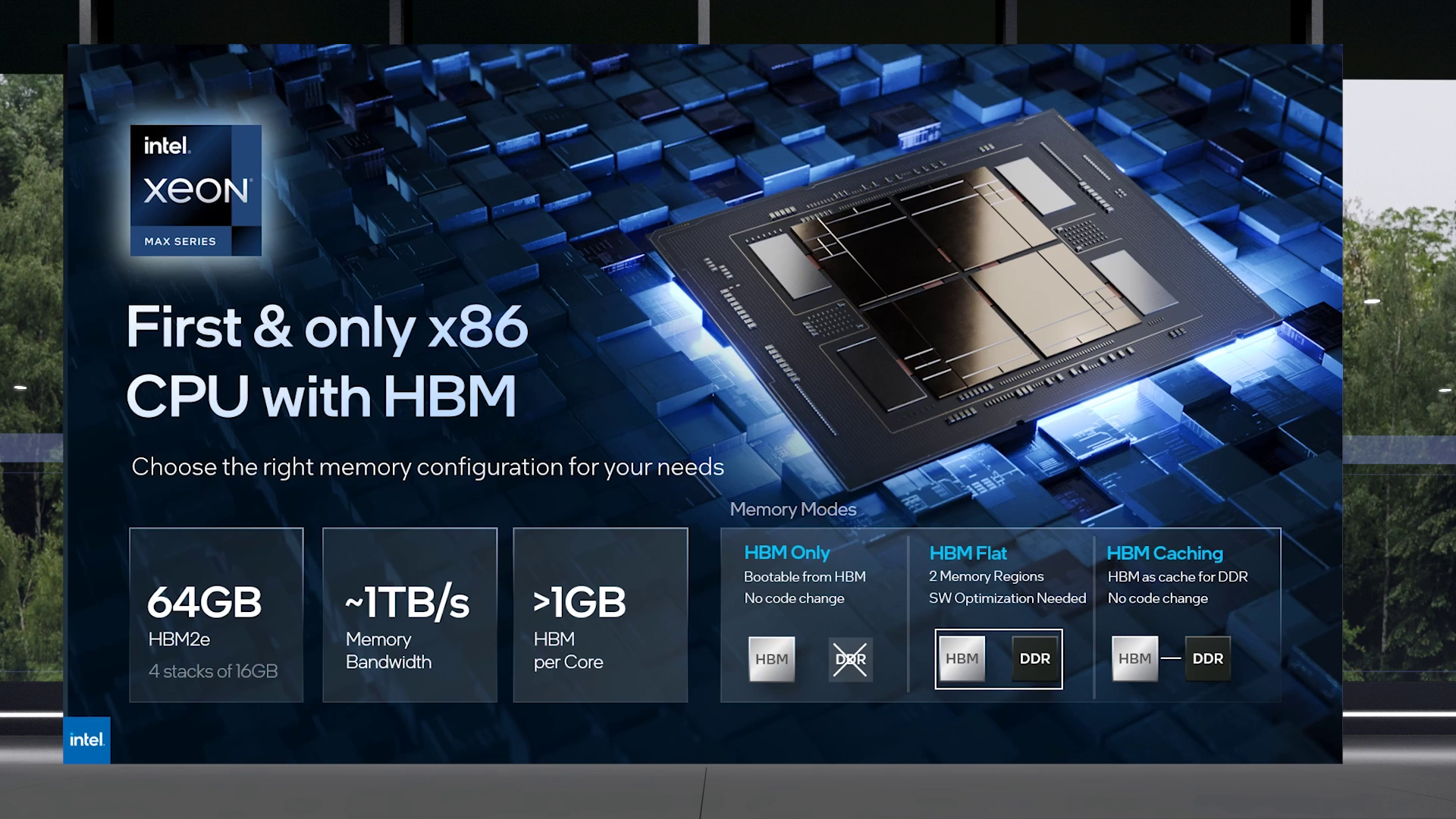 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA. |
|
